Check out our White Paper Series!
A complete library of helpful advice and survival guides for every aspect of system monitoring and control.
1-800-693-0351
Have a specific question? Ask our team of expert engineers and get a specific answer!
Sign up for the next DPS Factory Training!

Whether you're new to our equipment or you've used it for years, DPS factory training is the best way to get more from your monitoring.
Reserve Your Seat TodayData center uptime is mission-critical. Whether you're running your own facility or relying on third-party colocation and cloud providers, outages can completely stop your operations, disrupt customers, and cost your business millions.
Every year, Uptime Institute releases their Annual Outage Analysis to help operators understand exactly where the risks are growing, where they're shrinking, and where you should be paying the most attention.
The 2025 report has landed. The findings are both encouraging and unsettling. As a whole, outages are happening less frequently. However, when they do occur, they're increasingly complex, expensive, and difficult to prevent with simple fixes.
Let's break down exactly what Uptime Institute found, and - more importantly - what it means for your operations in 2025 and beyond.

First, the good news: outages are becoming less frequent over time. This is a direct result of billions of dollars in industry investment.
In the Uptime Institute 2024 Global Data Center Survey, only 53% of operators reported experiencing an outage in the past three years. That's down from 60% in 2022, 69% in 2021, and a huge 78% back in 2020. Clearly, improvements in redundancy, better operational discipline, and enhanced process management are helping prevent many of the routine failures that used to plague operators.
Even more promising is that the severity of these outages has decreased alongside their frequency. Only 9% of reported incidents in 2024 were classified as "serious" or "severe". This is the lowest number Uptime Institute has recorded since it began tracking this data.
At first glance, this suggests that our industry is winning the fight against downtime.
But things can get tricky here. Even as the overall numbers improve, the risks that remain are harder to predict, more complicated to diagnose, and potentially more catastrophic if you're caught unprepared.
One of the most important points in the report is this: "The slowdown in improvement does not imply complacency".
While many historical causes of outages are being better managed, new categories of risk are becoming more dominant. Many of these threats didn't even exist a decade ago.
The explosion of AI and machine learning workloads is forcing data centers to operate at new extremes. AI servers require massive power and generate enormous heat loads. According to Uptime, these demands are "straining existing infrastructure designs - especially around power and cooling".
Cooling systems are being pushed harder than ever. Electrical distribution gear must handle sustained high loads.
In many cases, facilities originally designed for traditional IT loads are being retrofitted on the fly. This introduces unforeseen single points of failure.
Global supply chains remain fragile. As Uptime notes in their report, "electricity grid limitations and global trade tensions introduce new uncertainty in supply chains and expansion plans."
If you need spare parts, new servers, or replacement HVAC components, you can get stuck with unexpected delays. Even routine maintenance windows can become riskier if you're waiting on gear that's stuck at a foreign port, requires payment of a tariff, and/or is backlogged for months.
Many organizations are increasingly relying on software-defined resiliency: virtualization, distributed load balancing, automated failovers, and hybrid-cloud models.
While these technologies have absolutely helped increase uptime in many cases, they also introduce new challenges. As Uptime warns, "added complexity brings its own challenges and can blur lines of responsibility for failures, complicating root cause analysis and outage classification".
When something breaks in a highly virtualized stack, figuring out exactly what broke and who is responsible is more difficult than ever.
Despite all the advancements in technology, power remains the most common root cause of serious outages. In fact, 54% of all impactful outages in 2024 were caused by power issues.
That includes:
And keep in mind, when a power failure strikes, it rarely stays contained. Cooling stops, batteries drain, racks go dark, systems crash, and data corruption becomes a very real risk.
Power failures cascade fast. You simply cannot afford to run your data center or telecom network without strong power monitoring and early-warning systems in place.
Right behind power on the list of root causes are IT and network failures.
In 2024, IT and networking issues were responsible for 23% of impactful outages. This is a noticeable increase from prior years.
This is likely because IT environments today are staggeringly complex. Software updates, patch management, API integrations, cloud interconnects, and hybrid WAN designs all add interdependencies that can fail in unpredictable ways.
Misconfigurations, firmware mismatches, untested failover paths, and overloaded routers have become increasingly common sources of downtime.
Root cause analysis is difficult. Blame can fall on the application team, the network engineers, the cloud provider, or even an unexpected interaction between all three.
Perhaps the most frustrating - and preventable - cause of outages is human error.
According to Uptime's 2025 report, 58% of human error-related outages were caused by staff failing to follow established procedures. That's a significant jump up from 48% the year prior.
The 2025 report also noted:
What's even more concerning is that 80% of operators believe their most recent downtime incident could have been avoided with better management, processes, or configuration.
These are mistakes that are (according to the people who know them best) completely preventable. However, this requires strong operational discipline, effective training, and real-time monitoring that can quickly alert staff to deviations before they spiral out of control.
Many organizations assume that outsourcing to cloud, SaaS, or colocation providers will shield them from the risks of downtime. But the data suggests otherwise.
Over nine years of tracking public outage reports, Uptime found that two-thirds of these outages involved third-party providers - including cloud, internet giants, telcos, and colo facilities.
Even hyperscale providers have suffered headline-grabbing failures. These often affect millions of end-users globally.
The lesson here is that you can't outsource responsibility for visibility. Whether your critical systems run on-premises, in a colo cage, or inside the public cloud, you still need comprehensive monitoring to detect - and react to - service interruptions right away.
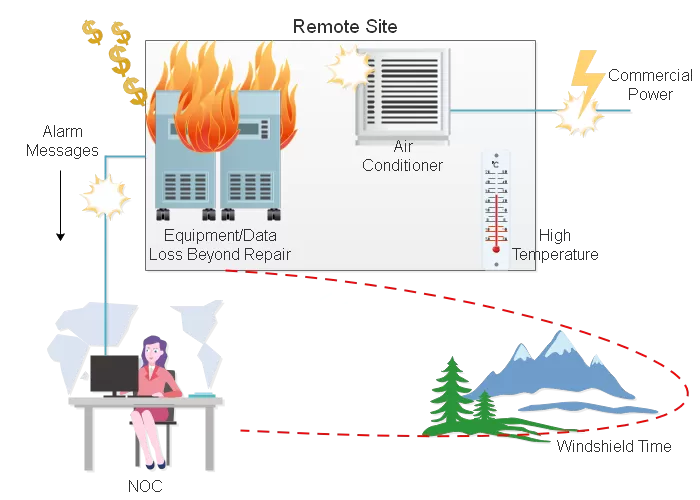
At DPS, we've spent over three decades helping telecom companies, utilities, railroads, and government agencies protect themselves against precisely the kinds of outages that are highlighted in the 2025 Uptime report.
Our flagship NetGuardian RTUs monitor every aspect of your site's power infrastructure:
With real-time alerts, you know the moment a failure begins. This allows you to take action before a full-blown outage develops.
By integrating automated control relays, escalation procedures, and clear notification paths, DPS systems help your staff avoid human-error mistakes:
When your teams get clear, actionable alarms, their chances of making mistakes drop dramatically.
DPS RTUs excel at simplifying messy "hybridized over time" networks. Our devices can:
This keeps your network health 100% visible, even as you have mixed and matched equipment vendors, software platforms, and cloud providers over the years.
Because DPS gear is fully vendor-neutral, you can monitor both "on-prem" and off-site infrastructure from a unified system. If your colo (colocation) provider, cloud vendor, or WAN carrier experiences trouble, you'll know about it immediately.
Unlike many generic "add-on" monitoring tools, DPS products are purpose-built for protecting your network and facilities from downtime.
That singular focus means we build gear that's:
When you're facing multi-million-dollar outage risks, you want monitoring solutions that were designed for this - not repurposed from unrelated product lines.
The 2025 Uptime Institute report makes one thing crystal clear: the risks aren't going away. They're simply evolving.
Your job is to build layers of visibility and control that let you respond before small incidents become costly disasters.
At DPS Telecom, that's all we do.
You don't need to navigate this complexity alone.
Give us a call at 559-454-1600 or email sales@dpstele.com
One of our engineers will walk you through your specific site challenges and show you proven solutions that are protecting real-world networks every day.
Let's make sure your organization isn't the next headline-making outage.

Andrew Erickson
Andrew Erickson is an Application Engineer at DPS Telecom, a manufacturer of semi-custom remote alarm monitoring systems based in Fresno, California. Andrew brings more than 19 years of experience building site monitoring solutions, developing intuitive user interfaces and documentation, and opt...


